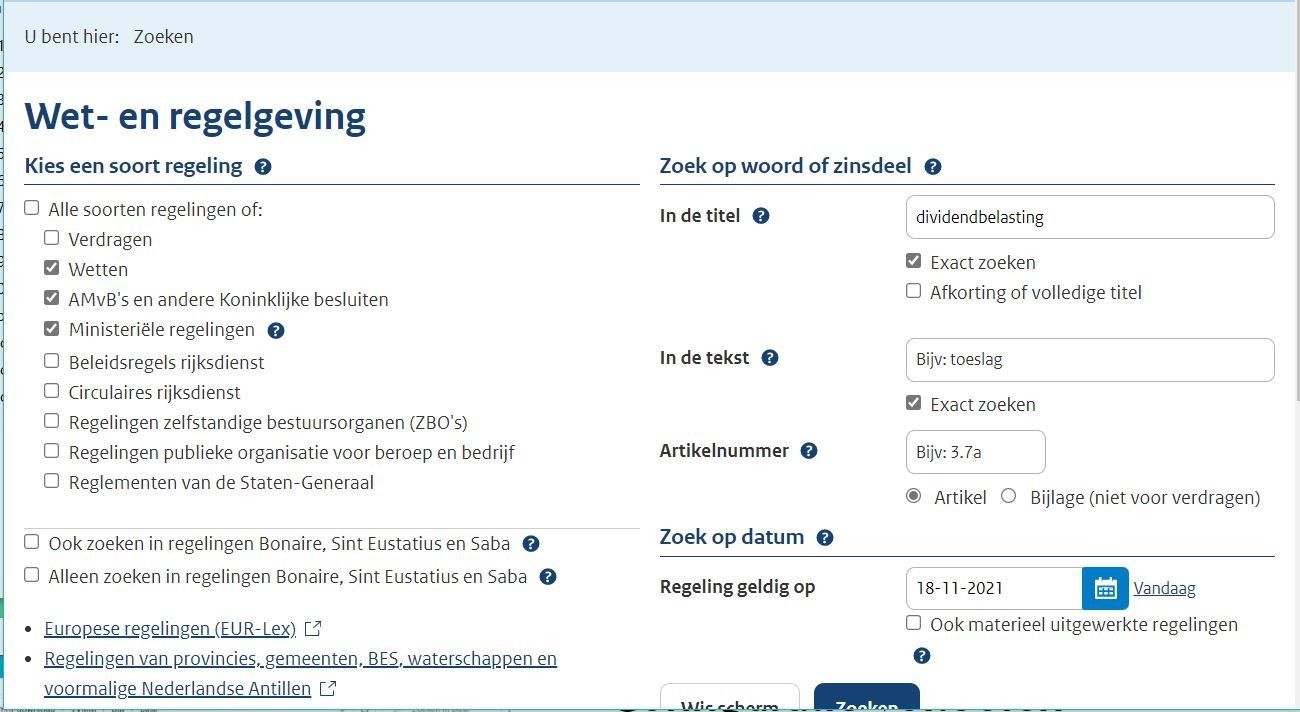
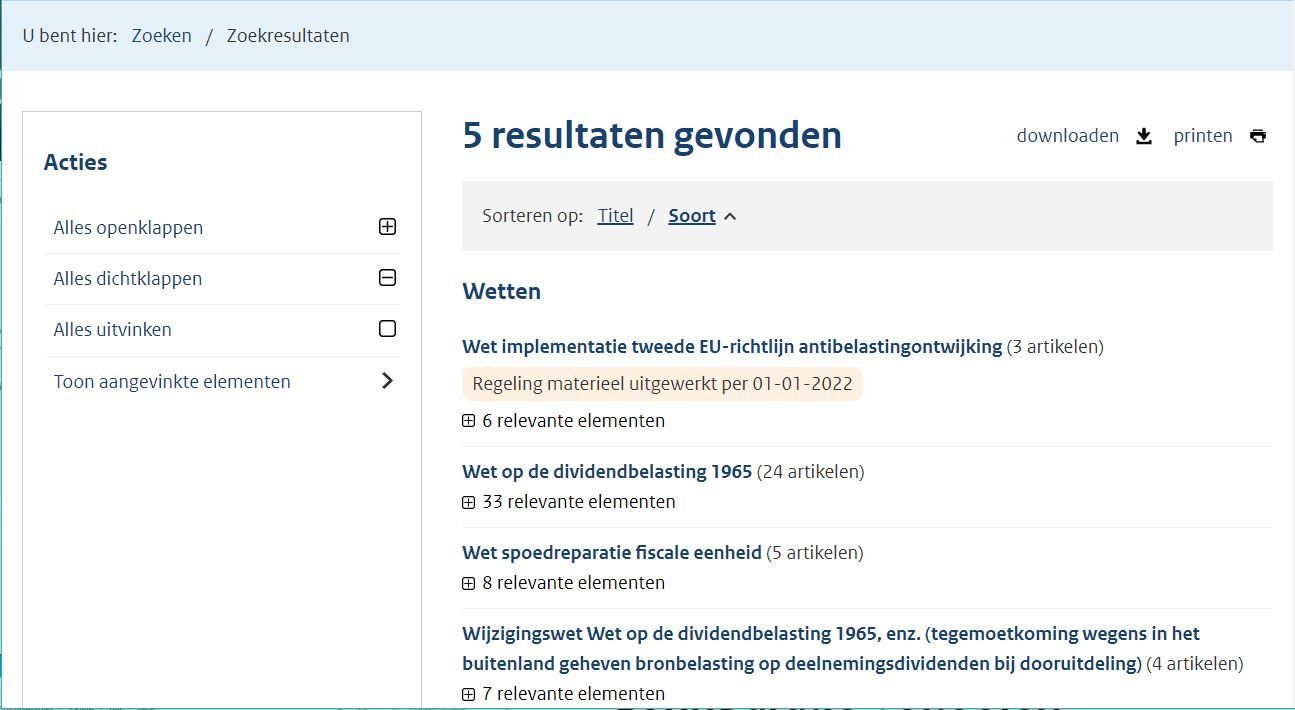
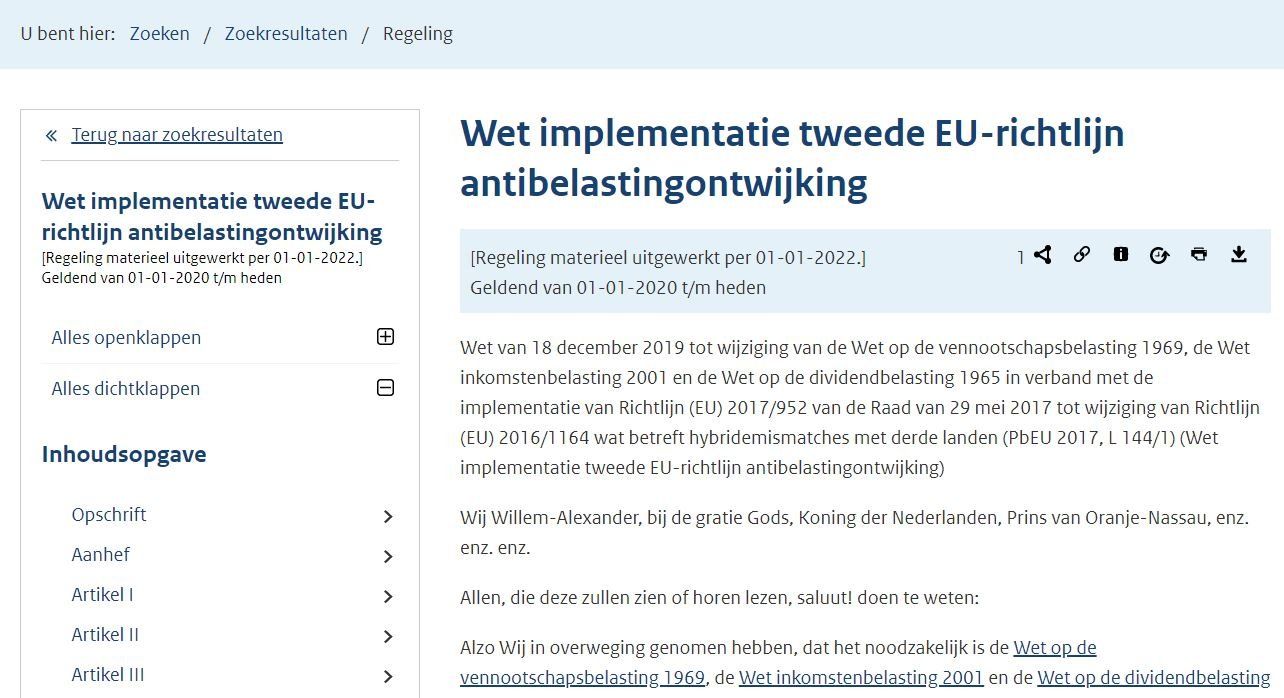
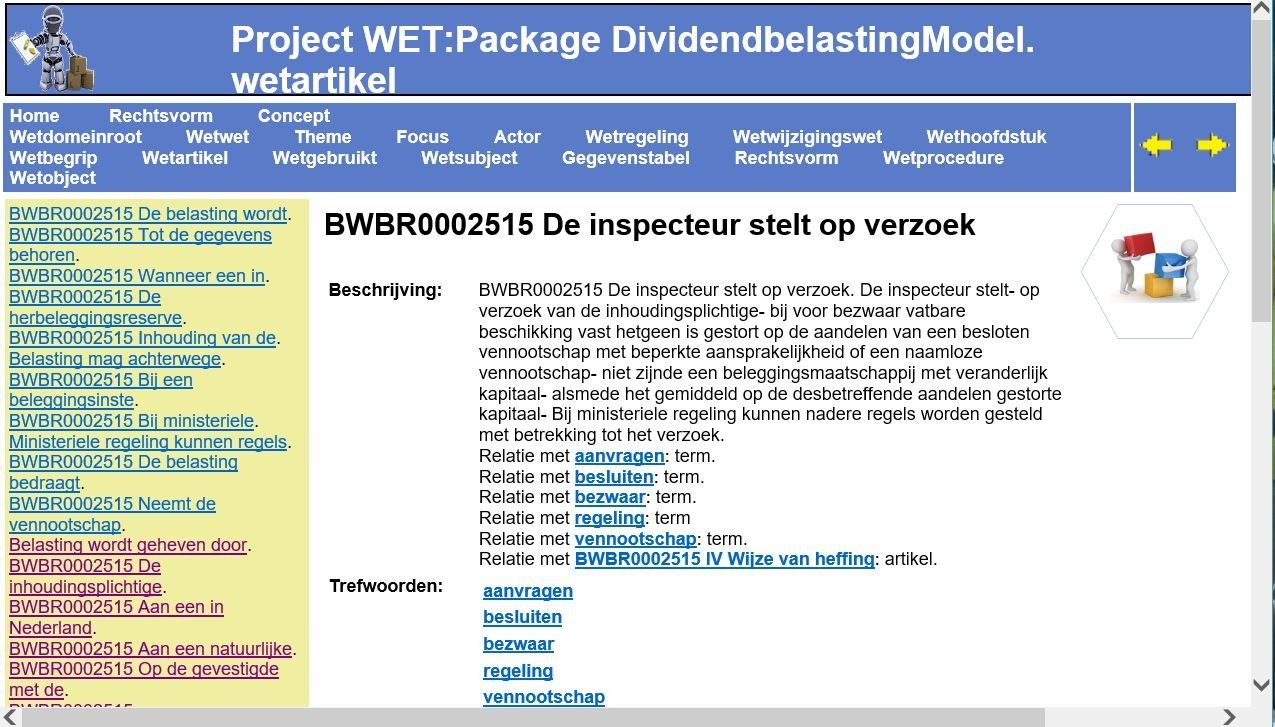
De hoofdstappen
Het gehele analyse proces bestaat uit de volgende stappen:
- Verzamelen van de informatie uit de wetten databank en maak de verzamelde bestanden gereed voor de analyse.
- Analyseren van de structuur van de bestanden en trefwoorden.
- Maak het model voor de wetgeving.
- De resultaten van de analyse publiceren
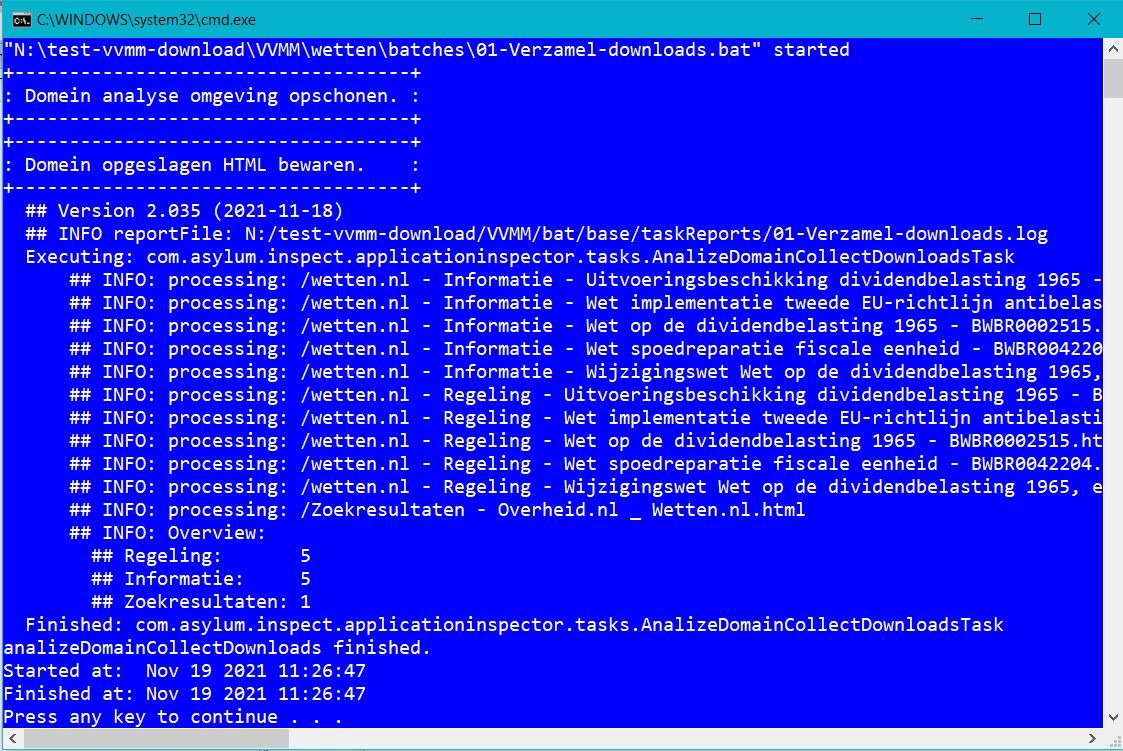
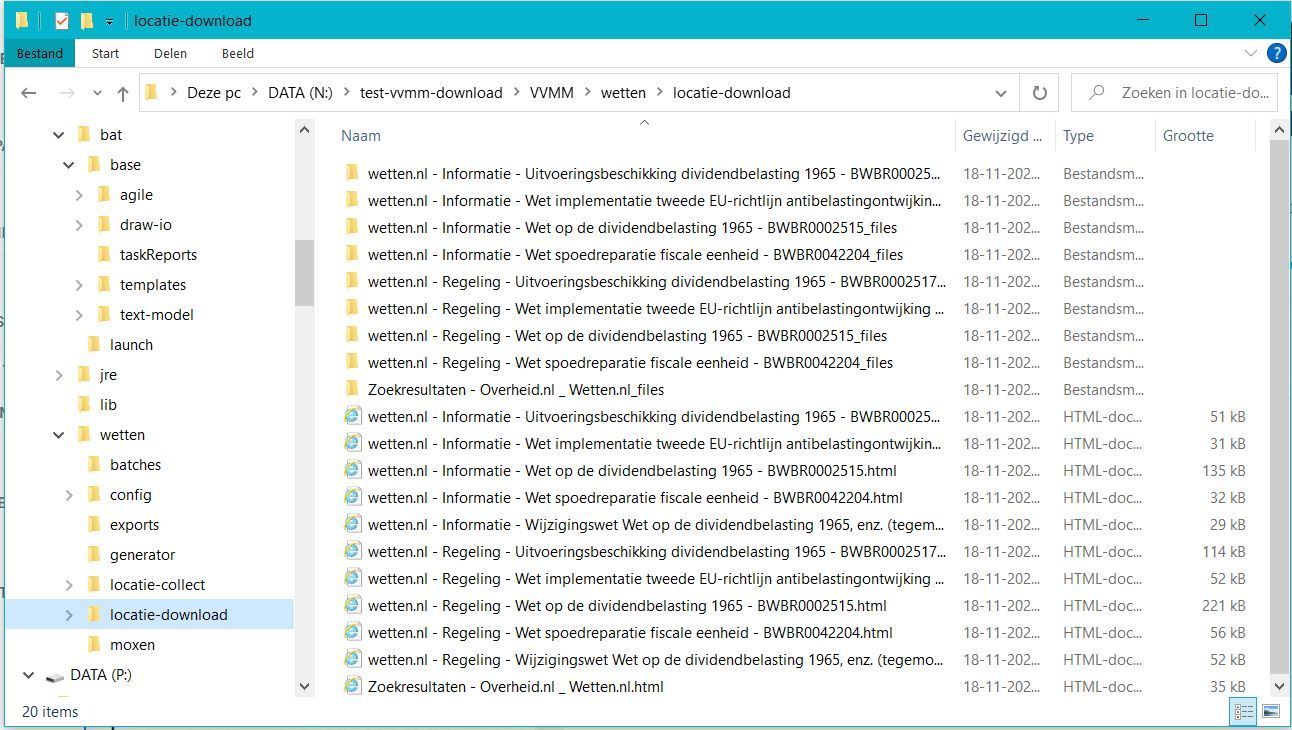
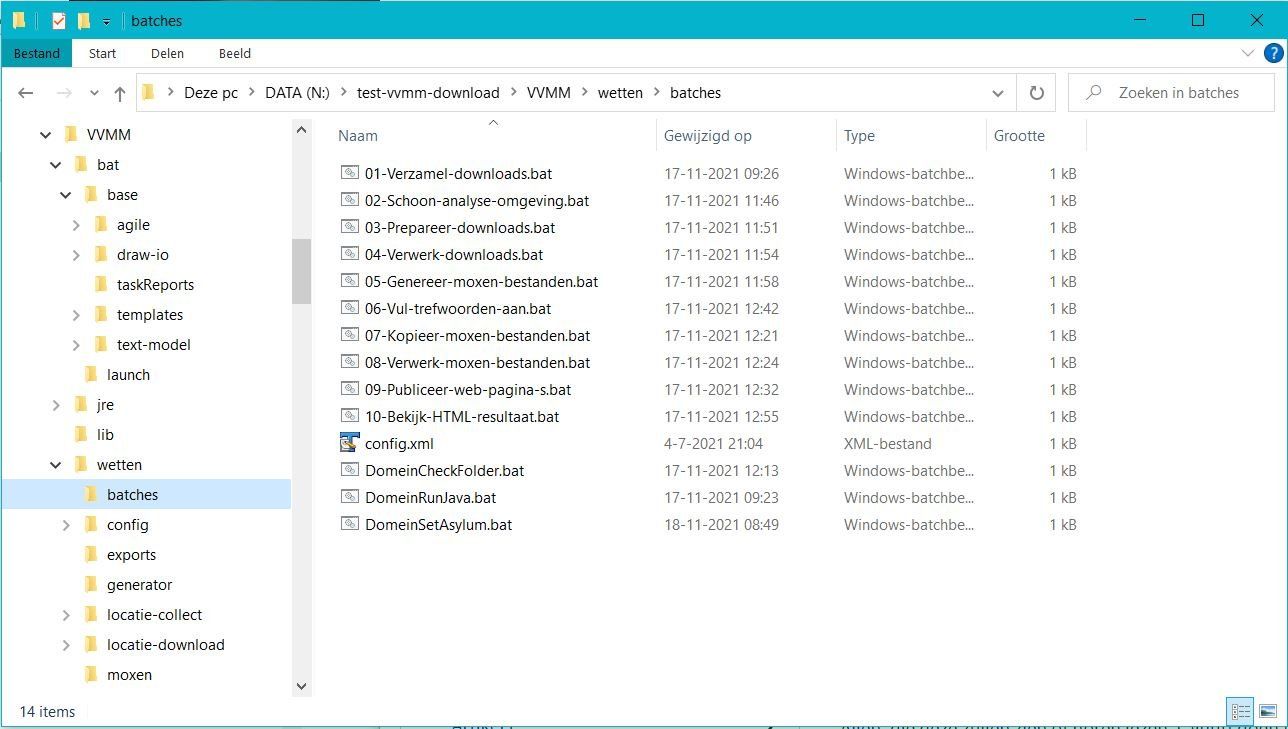
Bestanden gereedmaken voor analyse
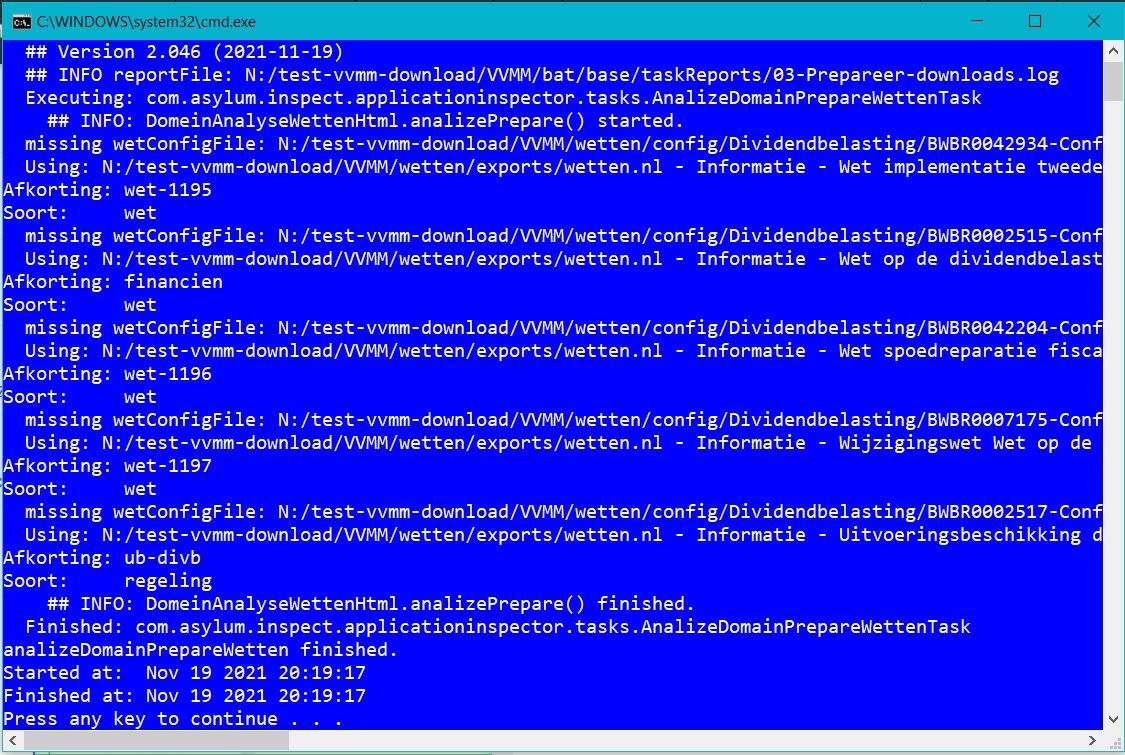
De bestanden die zijn vastgelegd moeten klaargezet worden om te worden geanalyseerd. Hiervoor moet het volgende worden gedaan.
- De bestanden die in de analyse worden betrokken worden gekopieerd naar een folder van waaruit je deze kunt gebruiken.
- De naam van de folder wordt afgeleid uit de zoekterm die je hebt gebruikt.
- Alleen de bestanden worden bewaard. De folders van de download mogen later worden verwijderd. Deze worden net gebruikt bij de analyse.
- Ook wordt gecontroleerd of de bestanden allemaal aanwezig zijn. Wanneer iets niet klopt wordt dit gemeld.
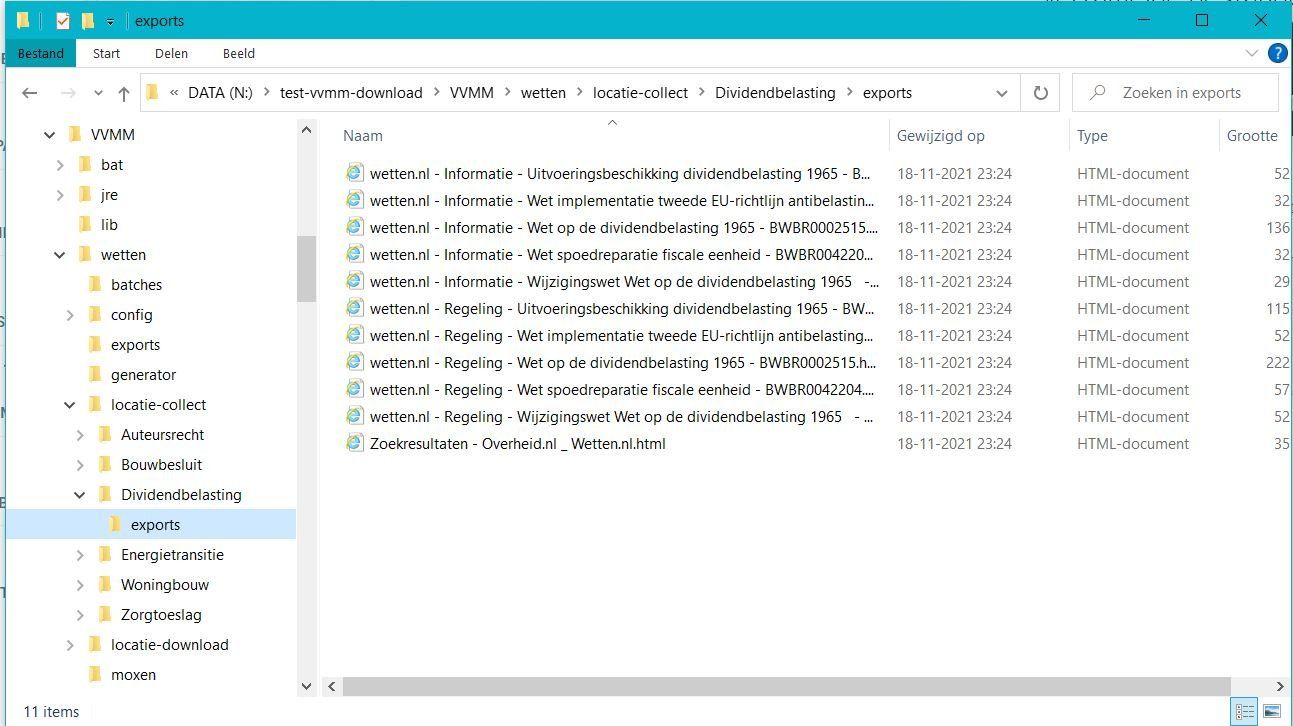
Structuur in de bestanden analyseren
De bestanden staan nu klaar in de folder "exports" om te worden geanalyseerd. Hierbij wordt het volgende gedaan:
- Uit de zoekterm wordt een naam voor het model bepaald.
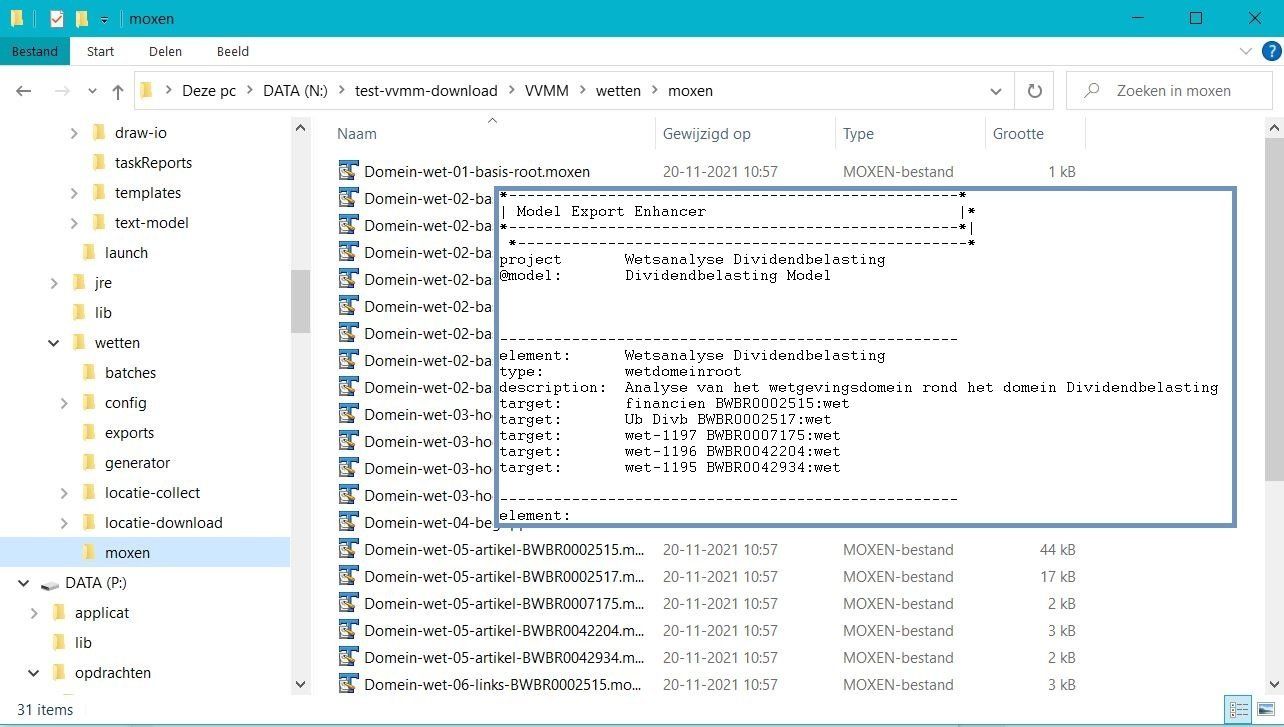
- De gegevens over een wettelijke tekst worden verzameld zoals de identificatiecode, wie voor de tekst verantwoordelijk is. wat het beleidsterrein is. Per tekst wordt een klein bestand aangemaakt met de naam die binnen het model wordt gebruikt.
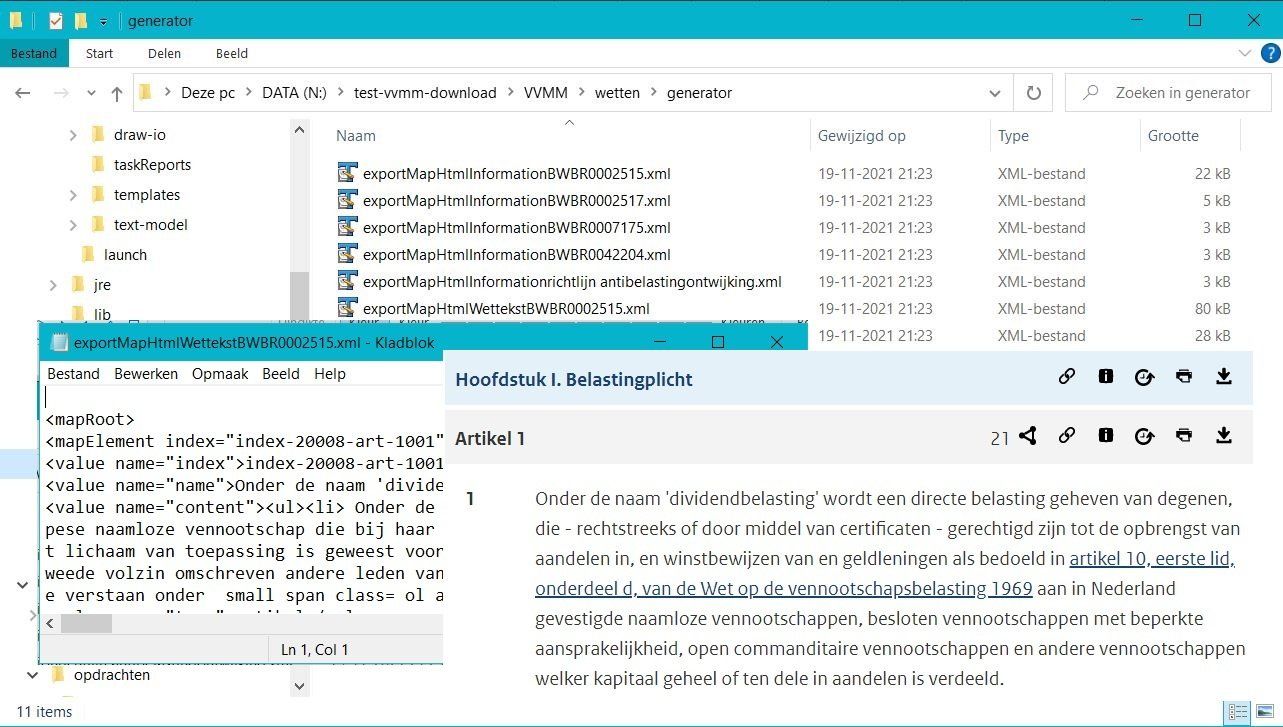
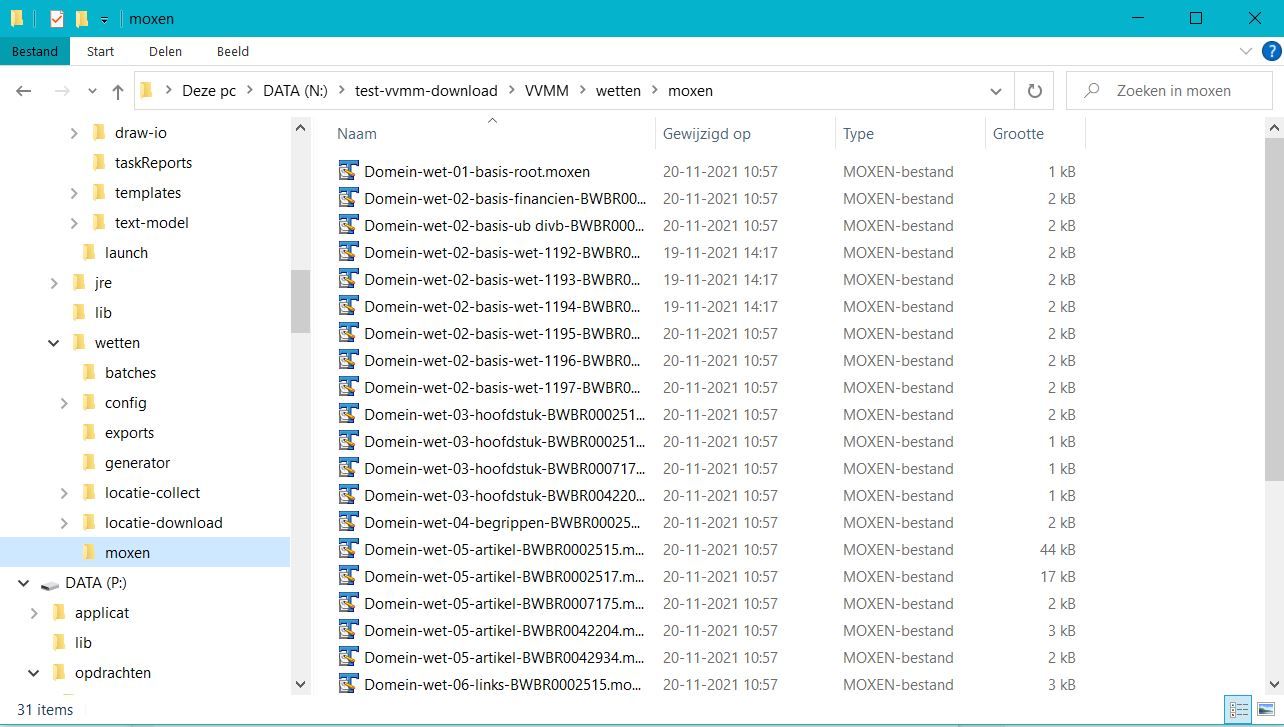
- De elementen in de tekst zoals hoofdstukken en artikelen met de daarin voorkomende tekst wordt overgenomen in een XML bestand. Verwijzingen naar andere weten komen daarin. Deze bestanden worden bijeengebracht in de folder "generator" voor de verzamelde wetten.
Instructies om model aan te maken
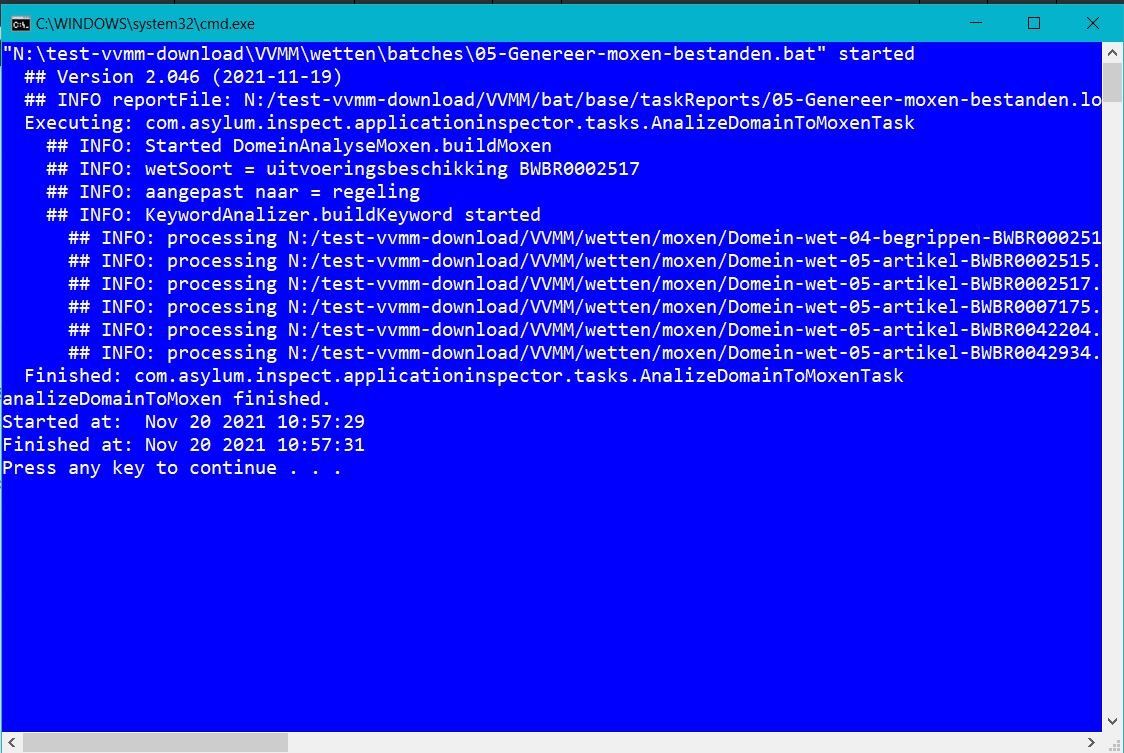
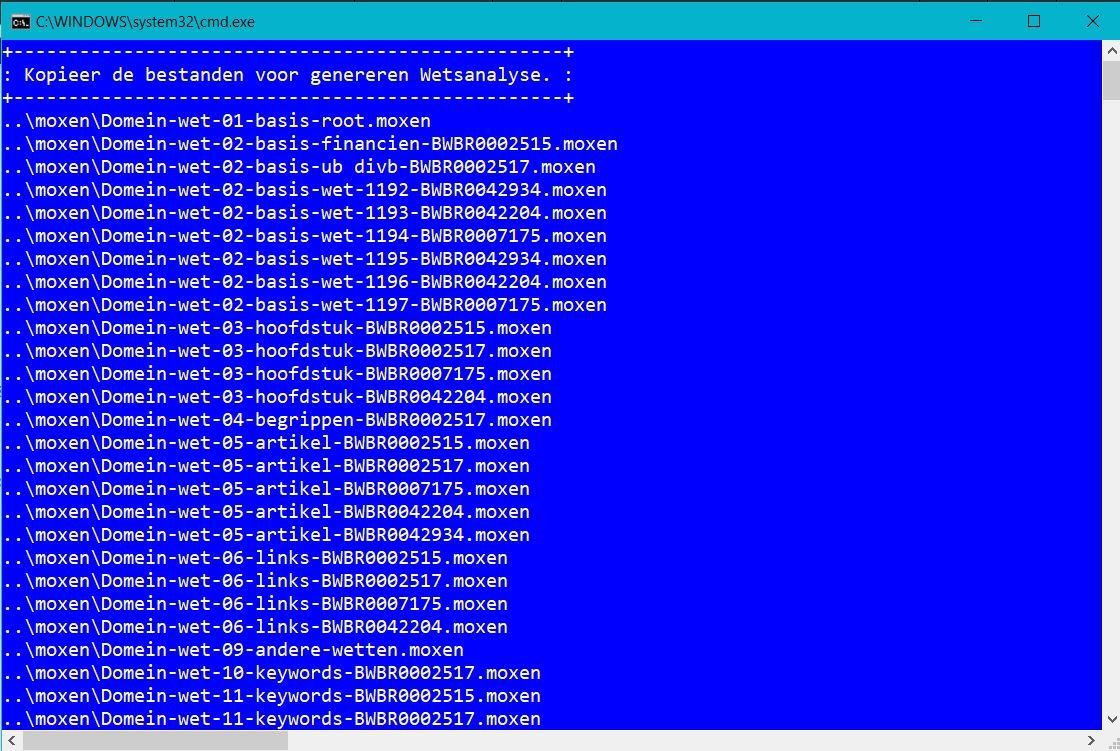
De bestanden die nu klaar in de folder "generator" worden omgezet naar '"moxen" bestanden om een model te genereren. Hierbij wordt het volgende gedaan:
- De informatie over wetteksten worden gecontroleerd op de voorwaarden om een model te maken. Dit is nodig omdat het soort wetgeving in de export niet altijd verband houdt met de structuur van een wettekst (Wet, AMvB, regeling, besluit).
- Per wettekst worden 'moxen' bestanden aangemaakt voor hoofdstukken en artikelen.
- Voor trefwoorden en relaties naar andere wetten worden afzonderlijke bestanden gegenereerd..
De bestanden komen in de folder "moxen" voor de verzamelde wetten.
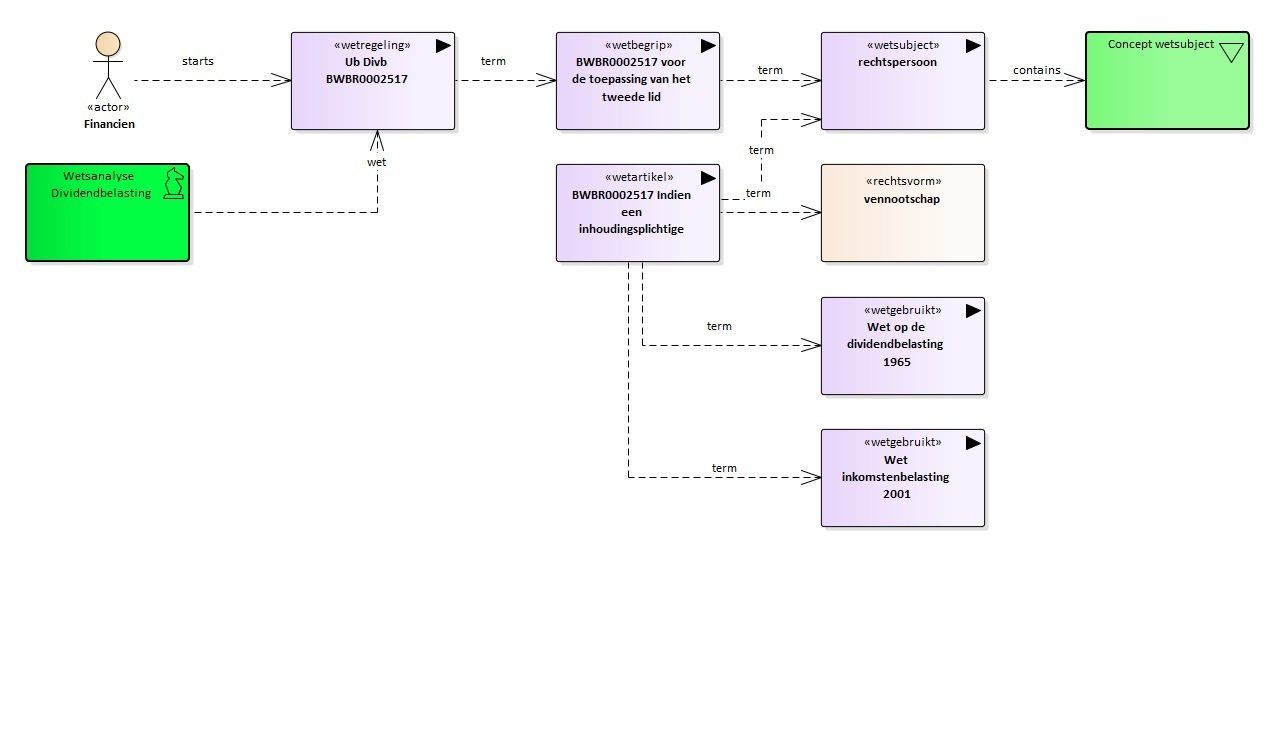
Het model genereren
De bestanden die nu klaar staan in de folder "moxen" worden gekopieerd naar de folder van waaruit de bestand worden omgezet naar een 'xmi' bestand.
Een 'xmi' bestand volgt de standaard indeling voor modellen die door een internationale commissie (OMG) is vastgesteld. Met een applicatie als "Enterprise Architect" kan je dit bestand inlezen en bewerken tot mooie diagrammen.
Het model publiceren
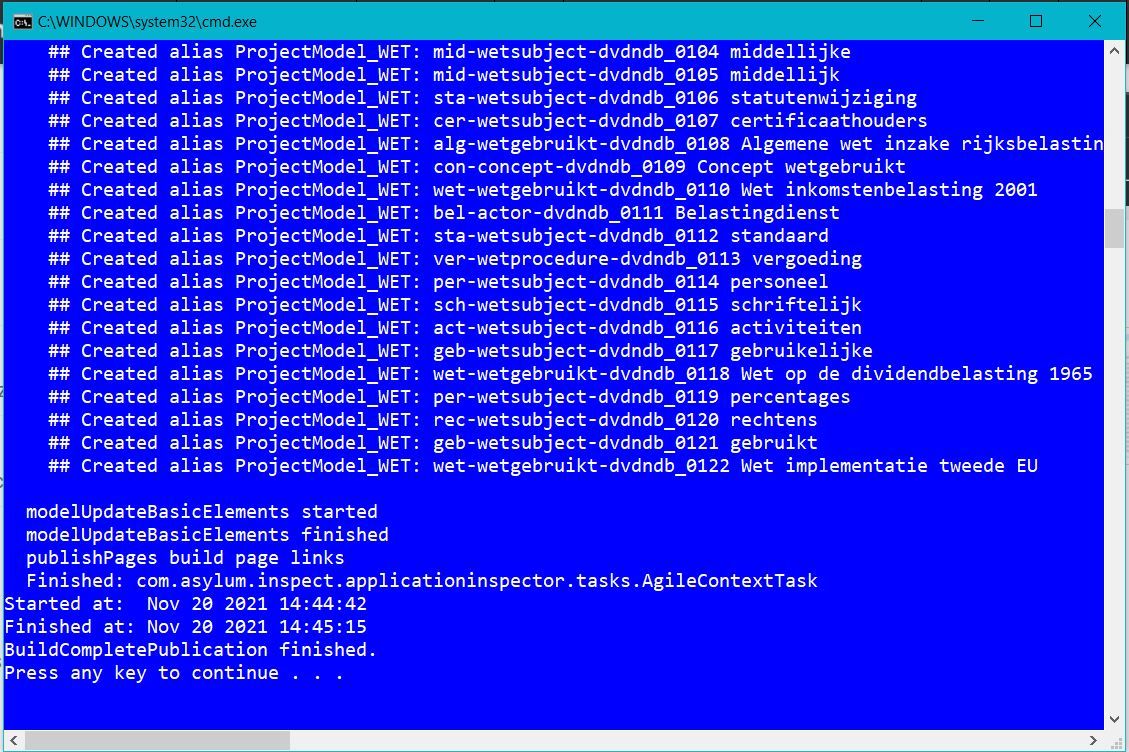
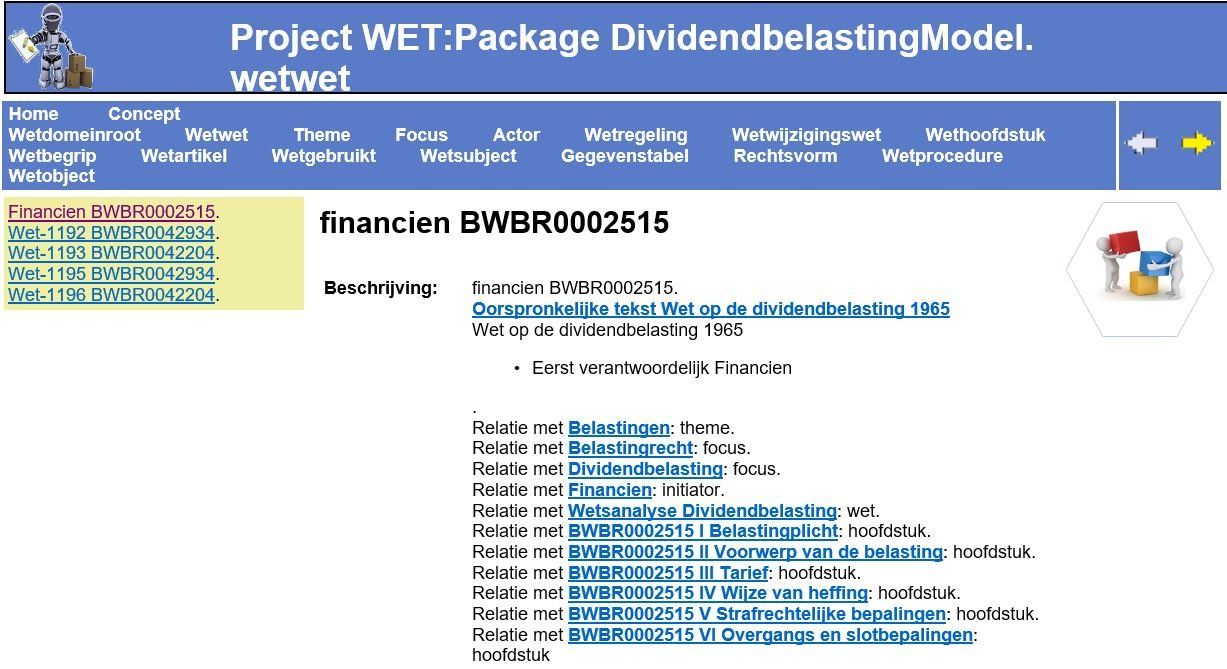
- Het 'xmi' bestand wordt verwerkt tot 'HTML' web pagina's. Deze pagina's bevatten de elementen uit het model en de relaties zijn omgezet naar links die je kunt aanklikken om zo via de relaties van element te navigeren.
De bestanden komen in de folder "htmlPages" voor de verzamelde wetten. Het genereren van de HTML kan enige tijd in beslag nemen. Voor het relatief kleine voorbeeld van de 'dividendbelasting' is dit ongeveer een halve minuut. Voor een groot voorbeeld als de 'AWB' kan dit ruim twee uur i beslag nemen. Je kunt dit afleiden uit het overzicht bij het inlezen. Voor het voorbeeld model zijn 122 elementen gevonden. Voor de 'AWB' gaat het om ruim 1200 elementen.